What Is A Cache Miss

When a processor looks for data in its memory hierarchy and cannot find it in the closest, fastest cache, that event is called a cache miss, and it has a direct impact on how quickly your applications run. Understanding this mechanism helps developers and system architects reduce latency, improve throughput, and design systems that spend less time waiting for data.
How a cache miss happens in the memory hierarchy
A cache miss occurs because modern computers use multiple layers of memory, each with different speed, cost, and capacity. The CPU registers are the fastest, followed by multiple cache levels (L1, L2, and often L3), then main memory (RAM), and finally slower storage like SSDs or hard disks. When the processor needs data, it first checks the closest cache level; if the data is not present, the request moves outward, and every step outward generally means higher latency and more cycles spent waiting.
In practice, a cache miss forces the processor to fetch data from a slower level of the hierarchy, which can stall pipelines, increase energy consumption, and degrade overall performance. The farther down the hierarchy the required data resides, the more expensive the access becomes in terms of time and power. This is why cache behavior is a central topic in computer architecture and performance engineering, since small improvements in cache hit rates can translate into large gains at the system level.

Types of cache misses and their causes
Not all cache misses are equal, and classifying them helps developers reason about where bottlenecks come from. The three standard categories are compulsory misses, capacity misses, and conflict misses, and each has distinct causes and implications for system design.
- Compulsory misses, also known as cold misses, happen the first time data is accessed because it has never been loaded into the cache yet. Even the most optimized code will experience these misses at startup when working sets are initially empty.
- Capacity misses occur when the working set of a program is larger than the available cache, so useful data is evicted and must be fetched again later.
- Conflict misses arise in set-associative caches when multiple frequently accessed data items map to the same cache set, causing unnecessary evictions even though the cache may technically have enough total space.
By distinguishing between these types, engineers can decide whether to improve algorithms, adjust data structures, increase cache size, or change associativity to reduce future misses.
The performance impact of a cache miss
The cost of a cache miss is measured in cycles, and the difference between a hit and a miss can be dramatic. On many modern processors, an L1 cache hit might take only a few cycles, while a miss that reaches main memory can cost tens or even hundreds of cycles. This gap creates what is commonly called the memory wall, where the CPU runs much faster than memory can supply data.
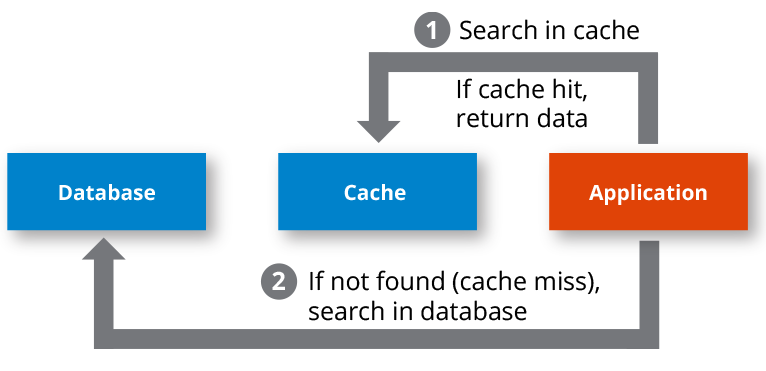
When misses happen frequently, pipelines may stall, out-of-order engines may run out of useful work, and applications can spend a large portion of their time waiting for data rather than computing. In latency-sensitive domains such as gaming, real-time systems, high-frequency trading, and large-scale databases, reducing cache misses is often more effective than simply increasing clock frequency, because memory access patterns dominate total execution time.
Strategies to reduce cache misses
Programmers and compiler writers use a variety of techniques to minimize cache misses, ranging from high-level algorithm choices to low-level optimizations. Improving data locality is the most powerful approach, because code that accesses memory in predictable, sequential patterns tends to make better use of cache lines and spatial locality.
- Temporal locality means reusing recently accessed data while it is still likely to be in the cache.
- Spatial locality means accessing data elements that are physically close in memory, taking full advantage of cache line fills.
- Data-oriented design encourages structuring programs around contiguous arrays and structures of arrays rather than arrays of structures, which can dramatically cut down on unnecessary cache fetches.
Other techniques include loop tiling or blocking, prefetching, reducing pointer chasing in data structures, and avoiding random access patterns in hot code paths. By carefully aligning algorithms with how caches work, developers can transform memory-bound code into compute-bound code, unlocking significant performance improvements without requiring more hardware.

Cache misses in real-world systems and workloads
The behavior of cache misses varies across workloads, and understanding this helps architects size caches and design balanced systems. In CPU-bound applications with tight loops over small datasets, miss rates can be extremely low, while in data-intensive workloads such as databases, analytics, and scientific simulations, misses can become the dominant cost.
Modern hardware counters and profiling tools expose metrics such as last-level cache misses, store misses, and miss rates per instruction, enabling developers to pinpoint hotspots where caching is inefficient. Virtual machines, containers, and shared cloud environments can introduce additional complexity, because noisy neighbors and scheduling decisions affect which data is resident in shared caches. As a result, performance engineering increasingly considers cache behavior at the level of entire systems, not just individual functions.
Looking ahead as memory and compute continue to evolve
Caches will remain a central mechanism for bridging the speed gap between processors and memory, even as new memory technologies and accelerators emerge. Future processors may introduce deeper cache hierarchies, larger last-level caches, and more sophisticated prefetchers, while software continues to adapt to these constraints. Emerging workloads such as machine learning and edge computing place new demands on caches, because they often mix irregular data access patterns with strict latency and power budgets.
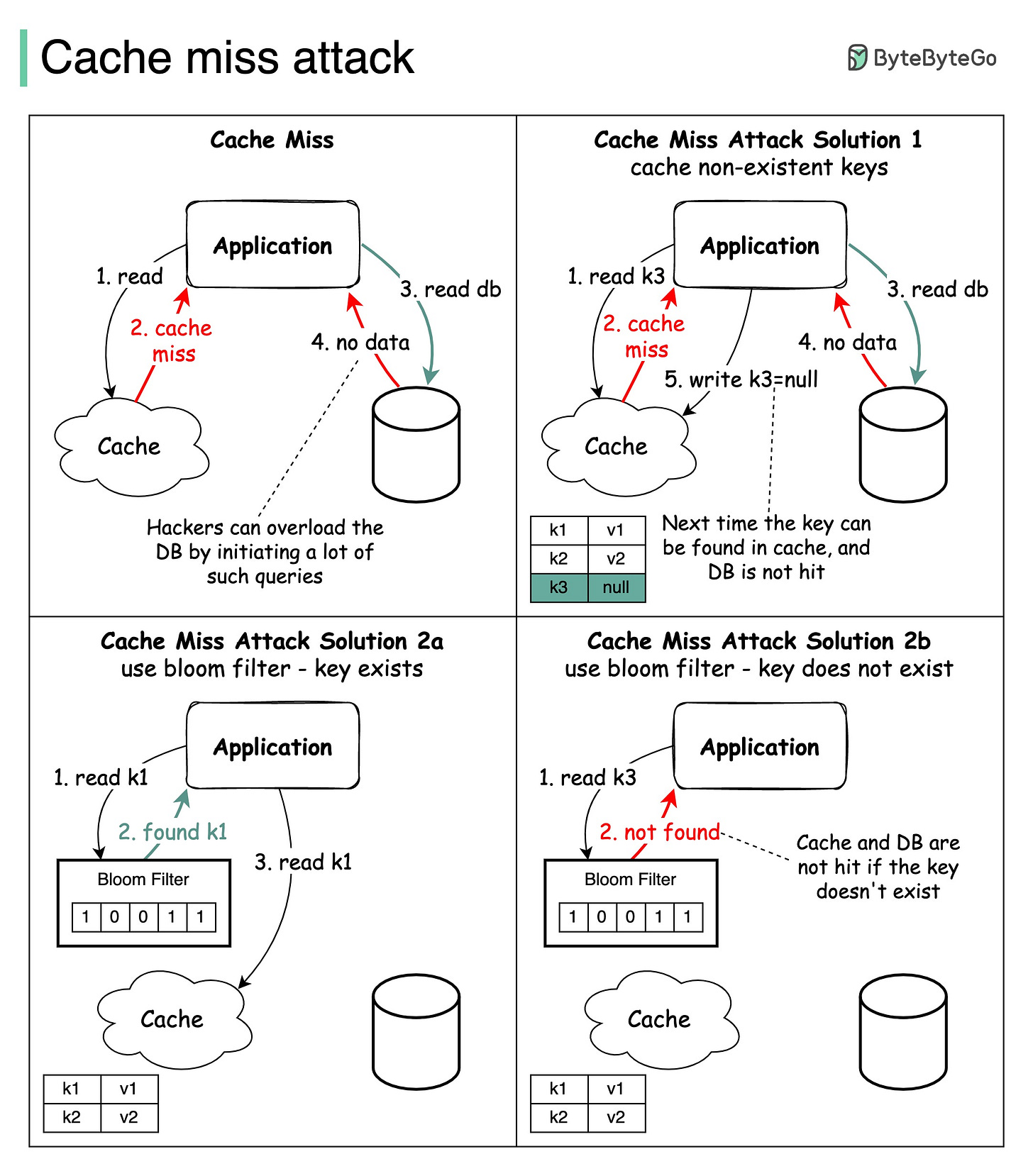
As architectures evolve, the fundamental principle stays the same: minimizing a cache miss is usually more effective than trying to speed up every individual memory access. By combining hardware insights with smart software design, teams can build systems that deliver high performance, low latency, and efficient use of energy, no matter how fast chips or memories become.
In summary, a cache miss is more than just a technical detail; it is a key concept that shapes performance engineering, algorithm design, and system architecture across the entire computing stack. Recognizing when and why misses happen empowers developers to make informed decisions that translate into faster, more responsive, and more efficient applications.
Cache Miss Types (Compulsory, Capacity, Conflict, Coherence)
Get the "Beginner's Guide to CPU Caches" E-Book at: ...
